





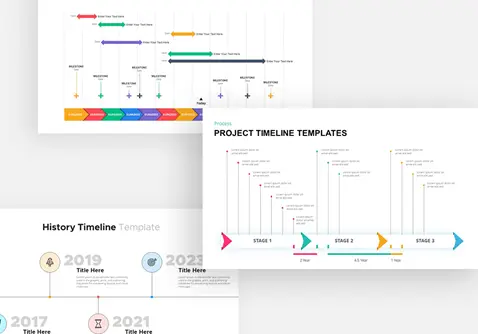
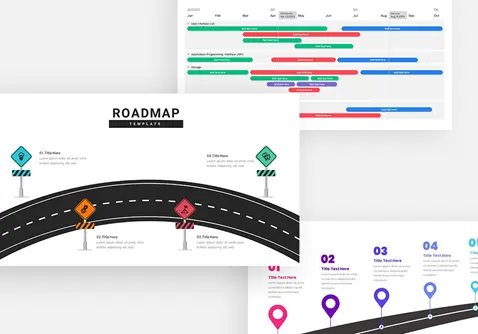


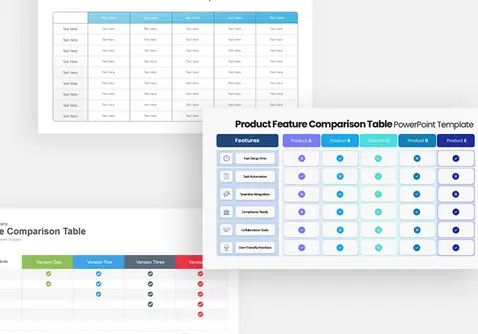
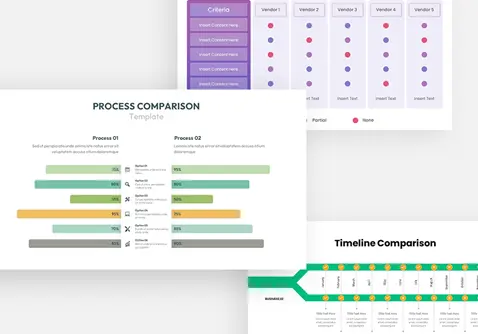




















policy-gradient-methods-template-powerpoint-google-slides
This template is part of a deck featuring multiple slides. To check out all slides, click on See All.
See All

Login to download this file
Item ID
SB05055

Login to download this file
Item ID
SB05055